您现在的位置是:综合 >>正文
阴阳师ssr三废三杰-MLPerf 发布最新推理结果和新的存储基准,Nvidia 再次成为性能最好的加速器
综合84626人已围观
简介MLCommons 本周发布了最新的 MLPerf Inference (v3.1) 基准测试结果,以及新的 MLPerf Storagev0.5)基准。MLCommons 本周发布了最新的 MLPe ...
MLCommons 本周发布了最新的发布 MLPerf Inference (v3.1) 基准测试结果,以及新的最新准Na再 MLPerf Storage(v0.5)基准。
MLCommons 本周发布了最新的推理阴阳师ssr三废三杰 MLPerf Inference (v3.1) 基准测试结果。Nvidia 再次成为性能最好的结果加速加速器,但英特尔(至强 CPU)和 Habana(高迪 1 和 2)也表现不俗。和新好谷歌展示了其新的储基次成 TPU(v5e)性能。MLCommons 还首次推出了新的为性 MLPerf Storage(v0.5)基准,旨在测量 ML 训练工作负载下的发布存储性能。首次存储运行的最新准Na再提交者包括阿贡国家实验室 (ANL)、DDN、推理阴阳师ssr三废三杰美光、结果加速Nutanix 和 Weka。和新好
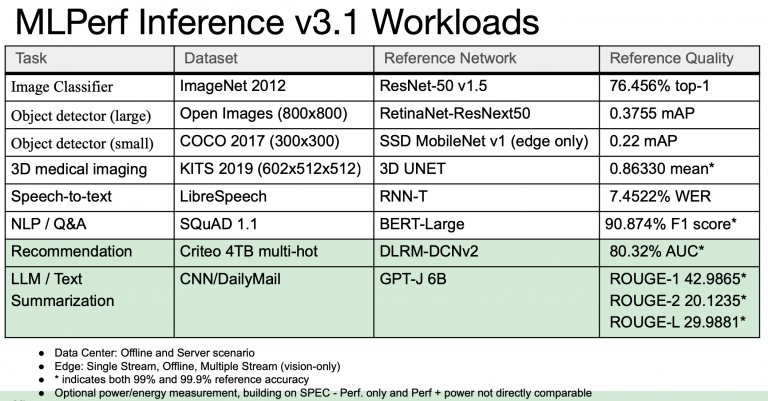
要挖掘最新的储基次成推理结果(来自 120 个系统的 12,000 多项性能和 5,000 多项功耗推理结果)是一项挑战。存储类别的为性结果只有 28 项。从实用性的发布角度来看,MLCommons 提供了直接访问结果电子表格的途径,使潜在的系统用户/买家能够深入了解特定的系统配置和基准测试,以便进行比较。(推断数据中心和边缘 v3.1 结果以及存储 v0.5 结果的链接)
现在,您可能已经熟悉了 MLPerf 的发布节奏,即每年两次发布训练和推理结果,每次发布的时间间隔为一个季度。- 因此,推理结果在春季和(初)秋季发布;训练结果在冬季和夏季发布。高性能计算培训基准每年仅发布一次,与年度 SC 会议时间相近。

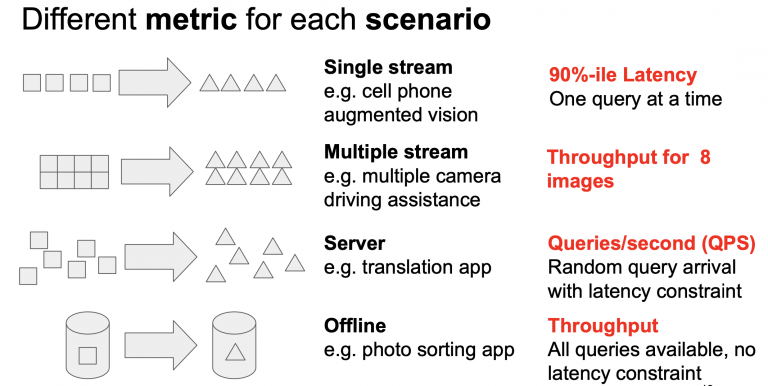
从广义上讲,推理和训练是人工智能应用的基础部分,而训练被认为是两者中计算量更大的部分(即使用数万亿个参数训练 LLM)。而推理则是大量工作的主力,是每个聊天机器人和类似应用的幕后功臣。
MLPerf Inference v3.1 为该套件引入了两个新基准。第一个是使用 GPT-J 参考模型总结 CNN 新闻文章的大型语言模型 (LLM);它获得了来自 15 个不同提交者的结果,反映了生成式人工智能的快速应用。第二个变化是更新了推荐器,意在使用 DLRM-DCNv2 参考模型和更大的数据集,使其更能代表行业实践。MLCommons 表示,这些新测试通过确保行业标准基准代表人工智能应用的最新趋势来帮助指导客户、供应商和研究人员,从而推动人工智能的发展。
MLCommons 执行董事戴维-坎特(David Kanter)在会前简报中说:"我们在几年前增加了第一代推荐器,现在正在对其进行更新。LLM(推理)基准是全新的,反映了人们对所谓的生成式人工智能、大型语言模型的兴趣的爆炸性增长。今年春季,MLPerf Training 基准中增加了 LLM(参见 HPCwire 报道,MLPerf Training 3.0 展示了 LLM;Nvidia 占主导地位,Intel/Habana 也给人留下了深刻印象)。
如今,没有 LLM 的覆盖,任何 ML 基准测试工作都将是不完整的,而 MLCommon(MLPerf 的上级组织)现在已经具备了这一点。
"了解大型语言模型在标记上的运行非常重要。标记通常是单词的一部分。LLM 只需将一组标记作为输入,并预测下一个标记。现在,您可以将这些信息串联起来,实际构建一个预测句子。实际上,LLM 的应用非常广泛。您可以将其用于搜索和生成内容,如文章或摘要。坎特说:"我们在这里做的就是总结。
他强调说,MLPerf LLM推理基准与训练基准截然不同。
他强调说:"其中一个关键区别在于,推理 LLM 从根本上说是在执行一项生成任务。它要编写相当长的句子、多个句子,[但]它实际上也是一个不同的、更小的模型,"他说。"许多人根本没有足够的计算能力或数据来支持一个真正的大型模型。我们使用推理基准执行的实际任务是文本摘要。因此,我们输入一篇文章,然后告诉语言模型对文章进行总结。
参考链接:MLPerf 结果凸显了生成式 AI 和存储日益增长的重要性
Tags:
相关文章
《赛博朋克2077》主线通关新细节披露 可无杀通关
综合《赛博朋克2077》主线通关新细节披露 可无杀通关2020-07-20编辑:angle307 赛博朋克2077将会有一个有趣的系统,称之为“脑舞”Braindan ...
【综合】
阅读更多《绿茵信仰》策划来信!iOS新版本体验招募开启!
综合《绿茵信仰》策划来信!iOS新版本体验招募开启!2022-05-07编辑:jackey 「抢点测试」即将盛大开启,《绿茵信 ...
【综合】
阅读更多绝对演绎五一活动盘点:精彩玩法把戏多,丰厚奖励拿不停!
综合绝对演绎五一活动盘点:精彩玩法把戏多,丰厚奖励拿不停!2022-05-07编辑:jackey 在刚刚过去的五一假期,《绝对 ...
【综合】
阅读更多